

Confira o resumo em áudio ☝️
🧩 Resumo
Este artigo apresenta uma análise sobre o processo de ETL (Extract, Transform, Load) e seu papel central na engenharia de dados. O texto descreve como o ETL transforma dados brutos e dispersos em informações estruturadas, confiáveis e úteis para a tomada de decisão. O ETL é mais do que um processo técnico: é a base que sustenta uma cultura data-driven sólida, capaz de transformar o caos dos dados em clareza estratégica.
📌 Direto ao ponto, o que você vai ver:
- O que é ETL e qual sua importância na engenharia e arquitetura de dados.
- As três etapas fundamentais: Extract, Transform e Load.
- Diferenças entre ETL e ELT e quando aplicar cada abordagem.
- Boas práticas para garantir qualidade, padronização e performance nos pipelines.
- Caso prático: o projeto “Saúde dos ETLs” desenvolvido pela Equal e sua contribuição para a confiabilidade dos dados.
______________________________
Vivemos uma era em que praticamente toda ação de uma empresa — uma venda realizada, um clique em um anúncio, um atendimento feito ou uma entrega atrasada — gera dados. O desafio não está apenas em coletá-los, mas em organizar, transformar e interpretar esse enorme volume de informações de forma que elas se tornem úteis e confiáveis para a tomada de decisão.
É nesse ponto que entra o ETL, um dos processos mais importantes (e muitas vezes invisíveis) dentro da engenharia e arquitetura de dados. Sem ele, as empresas até conseguem reunir dados de diversas fontes, mas dificilmente conseguem transformá-los em conhecimento estratégico.
O ETL — sigla para Extract, Transform, Load — representa as etapas fundamentais que permitem que dados brutos sejam extraídos de sistemas distintos, padronizados e carregados em um ambiente centralizado, como um data warehouse ou lakehouse. É essa base que alimenta dashboards, análises avançadas e até modelos de inteligência artificial.
Por isso, entender o que é ETL e como ele funciona vai muito além de um aspecto técnico: trata-se de compreender a espinha dorsal de qualquer estratégia de dados moderna. Sem um processo de ETL bem estruturado, não há BI confiável, automação eficiente ou cultura data-driven capaz de sustentar decisões de negócio sólidas.
Nos próximos tópicos, vamos explorar em detalhes o que é ETL, como ele funciona, quais são suas principais etapas e por que ele é essencial para quem deseja construir uma operação orientada por dados — com clareza, qualidade e velocidade.
Dependendo da ordem das etapas e dos serviços em que elas ocorrem, o processo pode se chamar “ELT”, sigla para Extract, Load, Transform – mais a frente no texto falaremos sobre esse processo também.
O que é ETL e como funciona o processo de Extract, Transform, Load
O termo ETL vem do inglês Extract, Transform, Load — que, traduzido, significa Extrair, Transformar e Carregar. Essas três etapas formam um dos pilares da engenharia de dados moderna, pois são responsáveis por preparar e mover as informações desde suas fontes de origem até um ambiente centralizado, onde poderão ser analisadas e transformadas em insights.
De forma simples, o ETL é o processo que garante que os dados certos cheguem ao lugar certo, no formato certo e no momento certo. Sem ele, os dados permaneceriam espalhados, inconsistentes e inutilizáveis — algo semelhante a tentar montar um quebra-cabeça com peças misturadas de diferentes jogos.
Extract (Extração): coletando dados de múltiplas fontes
A primeira etapa do ETL é a extração, que consiste em coletar dados de diferentes sistemas — planilhas, CRMs, ERPs, bancos de dados, plataformas de marketing, aplicações em nuvem e até sensores IoT.
O objetivo aqui é reunir tudo o que é relevante para a operação ou análise, independentemente do formato ou da origem. Essa fase exige conectores e integrações robustas, capazes de acessar dados em tempo real ou em lotes (batch).
É também nesse ponto que se definem quais dados realmente importam, evitando sobrecarregar a arquitetura com informações redundantes ou irrelevantes.
Uma boa prática nesta etapa é manter os dados no seu formato original. Se for uma extração via API, por exemplo, geralmente os dados são gravados em uma camada inicial em formato JSON. Da mesma forma, ao extrair dados de bancos de dados, normalmente utiliza-se formatos estruturados, como parquet e delta tables.
Transform (Transformação): limpando, padronizando e enriquecendo os dados
Depois de extraídos, os dados brutos passam pela fase de transformação — considerada o coração do processo ETL. Aqui ocorre a limpeza, padronização, validação e enriquecimento das informações para garantir que elas possam ser usadas com segurança nas análises.
Entre as tarefas mais comuns dessa etapa estão:
- remoção de duplicidades e erros;
- padronização de formatos (como datas e moedas);
- cruzamento de informações entre diferentes sistemas;
- criação de novos campos calculados;
- anonimização de dados sensíveis, atendendo à LGPD.
É nessa fase que os dados deixam de ser apenas “matéria-prima” e se tornam insumos confiáveis para dashboards, relatórios e modelos preditivos.
Considerando que os jobs de transformação podem ser feitos por vários desenvolvedores, uma boa prática nesta etapa é ter um padrão para transformar os dados. Atualmente, existem infinitas bibliotecas e maneiras diferentes de aplicar transformações, porém algo que todos os engenheiros de dados têm em sua stack é SQL. Portanto, transformações em SQL são sempre uma boa opção, podendo ser usadas com Spark SQL, por exemplo.
Load (Carga): entregando os dados processados ao destino final
Por fim, os dados transformados são carregados (load) para um ambiente centralizado e estruturado — geralmente um data warehouse, data lake ou lakehouse. Esse é o espaço onde as informações ficam disponíveis para o time de BI, analistas e cientistas de dados realizarem consultas e análises de maneira ágil e integrada.
Dependendo da arquitetura e da maturidade da empresa, essa carga pode acontecer em lotes programados (por exemplo, diariamente) ou de forma contínua e automatizada, garantindo atualizações quase em tempo real.
Uma analogia simples: o ETL é a cozinha dos dados
Imagine uma cozinha profissional. Os ingredientes (dados brutos) chegam de diferentes fornecedores — alguns frescos, outros processados, outros embalados.
O cozinheiro (o pipeline ETL) seleciona, lava, corta, tempera e combina esses ingredientes, transformando-os em um prato pronto, saboroso e padronizado (os dados tratados). Por fim, o prato é servido no restaurante (data warehouse), pronto para ser consumido pelos clientes (os usuários de negócio e analistas).
Da mesma forma, o ETL transforma o caos dos dados em informação organizada, confiável e pronta para consumo. É o que permite que uma empresa enxergue seus resultados de forma integrada — e tome decisões com base em fatos, não em suposições.
Qual a importância do ETL na engenharia de dados moderna
O ETL é, em essência, a espinha dorsal da arquitetura de dados moderna. É o processo que conecta todas as camadas do ecossistema analítico — desde as fontes de informação até os dashboards e modelos de inteligência artificial. Sem ele, não existe consistência, rastreabilidade nem confiança nas análises que orientam a tomada de decisão.
Um dashboard de BI é tão bom quanto os dados que o alimentam. E a qualidade dos dados começa no pipeline. Durante o processo de transformação, o ETL limpa, valida e padroniza informações, eliminando erros, duplicidades e inconsistências. Esse cuidado técnico é o que permite que relatórios de diferentes áreas — como Vendas, Financeiro e Marketing — apresentem números coerentes entre si.
Além disso, o ETL desempenha um papel fundamental na governança de dados:
- define regras de acesso e segurança, respeitando normas como a LGPD;
- assegura rastreabilidade, permitindo saber de onde cada dado veio e como foi transformado;
- cria uma camada de padronização que sustenta a integridade da informação ao longo de todo o ciclo analítico.
Quando o ETL é bem implementado, a empresa passa a confiar nos próprios dados — e isso é o que diferencia organizações verdadeiramente data-driven daquelas que apenas acumulam planilhas.
O mesmo vale para modelos de inteligência artificial: sem dados limpos, normalizados e padronizados, os algoritmos aprendem padrões incorretos e produzem previsões distorcidas. Por isso, o ETL é uma etapa crítica também para projetos de machine learning e data science. É ele que dá sustentação ao que se chama de “treinamento ético e confiável” de modelos de IA.
As consequências de um ETL mal estruturado
Quando o ETL é negligenciado ou mal projetado, os impactos aparecem rapidamente:
- erros em relatórios e indicadores, gerando desconfiança interna;
- retrabalho constante, com analistas tentando corrigir inconsistências manualmente;
- decisões equivocadas, tomadas com base em dados incorretos;
- custos operacionais altos, já que o time precisa revisar ou refazer processos repetidamente;
- e até riscos de conformidade, caso dados sensíveis sejam tratados sem os devidos controles.
Em resumo, um ETL mal estruturado pode comprometer toda a estratégia de dados de uma organização. Por outro lado, quando bem planejado, ele se torna um diferencial competitivo — permitindo que a empresa opere com dados de qualidade, análises confiáveis e performance analítica sustentável.
ETL x ELT: qual a diferença e quando usar cada um
Com a evolução das tecnologias de dados, o processo de ETL passou por uma transformação significativa. Nos ambientes tradicionais, ele era a única forma viável de preparar os dados para análise.
Mas com o avanço das plataformas em nuvem — como Databricks, BigQuery, Snowflake e Azure Synapse — surgiu uma variação desse processo: o ELT, que inverte parte da lógica clássica e traz novas possibilidades de performance e escalabilidade.
Apesar das semelhanças, ETL e ELT não são a mesma coisa. Cada abordagem tem características próprias e se adequa melhor a determinados contextos.
Diferença técnica entre ETL e ELT
A principal diferença entre os dois processos está na ordem em que as etapas de transformação e carga são executadas:
- ETL (Extract, Transform, Load): os dados são extraídos, transformados em um ambiente intermediário (geralmente um servidor dedicado ou ferramenta de integração), e só então carregados para o destino final, como um data warehouse.
→ Esse modelo é ideal quando há necessidade de padronizar e limpar dados antes do armazenamento, garantindo que apenas informações tratadas cheguem ao destino.
- ELT (Extract, Load, Transform): aqui, os dados são extraídos e carregados diretamente no destino — normalmente uma plataforma em nuvem de alta performance — e transformados dentro do próprio ambiente de armazenamento.
→ Nesse modelo, as transformações são executadas no banco de dados de destino, aproveitando o poder computacional da nuvem e reduzindo o tempo de movimentação de dados.
Como a arquitetura moderna de dados transformou esse processo
Com o surgimento dos Data Lakes e, mais recentemente, das arquiteturas Lakehouse, a forma de lidar com dados se tornou mais flexível e escalável. Essas plataformas conseguem armazenar tanto dados estruturados (como planilhas e tabelas) quanto não estruturados (como imagens, logs e arquivos JSON) — o que ampliou as possibilidades de integração e análise.
Ferramentas como Databricks, BigQuery e Snowflake permitem processar grandes volumes de dados diretamente no ambiente de destino, tornando o ELT mais eficiente e acessível.
Em vez de sobrecarregar servidores intermediários, as transformações passam a ser realizadas por engines altamente otimizadas e elásticas, com capacidade de escalar automaticamente conforme a demanda.
Além disso, a combinação de pipelines automatizados e processamento em paralelo viabilizou fluxos contínuos e quase em tempo real, aproximando o conceito de DataOps — em que os pipelines de dados são tratados com a mesma agilidade e controle das operações de software.
ETL e ELT não competem — se complementam
Em muitas empresas modernas, o que existe é um ecossistema híbrido, onde ambos os modelos coexistem. O ETL continua sendo usado para fluxos críticos e altamente controlados, enquanto o ELT ganha espaço em pipelines de dados exploratórios, automatizados e voltados para analytics e IA.
Mais importante do que escolher entre um e outro é garantir que o processo de ingestão e transformação de dados seja confiável, escalável e rastreável — e é isso que diferencia uma arquitetura moderna de dados de um simples conjunto de integrações desconectadas.
Boas práticas de ETL para garantir qualidade e performance
Um pipeline de ETL eficiente não depende apenas de boas ferramentas — ele exige disciplina técnica, padronização e governança. Essas boas práticas são o que asseguram que os dados percorram todo o fluxo de extração, transformação e carga com qualidade, rastreabilidade e segurança.
Na engenharia de dados moderna, a performance do ETL está diretamente ligada à sua capacidade de manter processos limpos, automatizados e auditáveis.
Entre os principais pilares para garantir um ETL robusto e de alto desempenho.
1. Padronização de formatos e nomenclaturas
A primeira regra de um pipeline sustentável é a consistência. Definir padrões claros para nomes de tabelas, colunas, diretórios, variáveis e tipos de dados evita confusão, retrabalho e erros de integração.
Por exemplo, usar convenções como snake_case ou camelCase de forma uniforme e definir regras de nomenclatura por domínio de negócio (ex: vendas_cliente, financeiro_transacao) contribui para a legibilidade e escalabilidade da arquitetura.
Além disso, manter padrões de formato — como data em ISO (YYYY-MM-DD), moedas em valores numéricos padronizados e campos categóricos normalizados — garante que diferentes sistemas consigam conversar entre si sem ruídos.
2. Testes e validação de dados em cada etapa
A etapa de transformação é o ponto mais sensível do ETL — e também o momento ideal para aplicar testes automatizados de qualidade. Esses testes verificam se as regras de negócio foram aplicadas corretamente e se os dados mantêm integridade ao longo do processo.
Entre os tipos de validação mais comuns estão:
- validação de schema (tipos de dados esperados, campos obrigatórios, formatos válidos);
- validação de volume (verificação de perda ou duplicação de registros);
- validação de regras de negócio (ex: “nenhuma venda pode ter valor negativo”);
- checagem de integridade referencial (relacionamentos entre tabelas).
Essa prática assegura que os dados entregues ao data warehouse ou lakehouse estejam sempre corretos e prontos para uso, sem surpresas desagradáveis nos dashboards.
3. Documentação e versionamento
Um ETL eficiente precisa ser bem documentado e versionado — tanto para fins técnicos quanto de governança. A documentação deve descrever a origem dos dados, as transformações aplicadas, as dependências entre tabelas e os agendamentos.
Isso facilita a manutenção, acelera o onboarding de novos analistas e reduz o risco de gargalos operacionais. Hoje em dia, plataformas como Databricks fornecem diagramas de hierarquia de tabelas automaticamente, além de facilitar a inclusão de descrições nas tabelas com IA.
O versionamento de código, por sua vez, é indispensável. Ferramentas como Git permitem controlar mudanças, criar históricos de alterações e reverter versões em caso de falha. Tratar pipelines como código (Data as Code) é uma das bases do conceito de DataOps, que traz para o mundo dos dados as boas práticas de desenvolvimento de software.
🧭 A clareza da documentação é o que garante que o conhecimento não fique concentrado em pessoas, mas institucionalizado em processos.
4. Governança e segurança (compliance e LGPD)
Por fim, nenhuma arquitetura de ETL é completa sem uma camada sólida de governança e segurança. Cada etapa do pipeline precisa respeitar as políticas internas da empresa e legislações como a LGPD (Lei Geral de Proteção de Dados).
Isso inclui:
- controlar quem pode acessar e manipular os dados;
- aplicar anonimização ou mascaramento de informações sensíveis (como CPF, e-mail, dados financeiros);
- registrar logs de acesso e transformação para auditorias;
- e implementar mecanismos de criptografia em trânsito e em repouso.
Essas práticas não são apenas exigências legais — são diferenciais competitivos para empresas que buscam operar de forma ética, transparente e confiável.
ETL de alta performance é mais do que técnica — é cultura
Boas práticas de ETL refletem o nível de maturidade de uma organização em relação aos seus dados. Quando a padronização, o monitoramento, os testes e a governança são parte natural do processo, a empresa deixa de apenas “fazer ETL” e passa a viver uma cultura data-driven com responsabilidade e eficiência.
Em última instância, um ETL bem estruturado não apenas processa dados — ele garante a confiança necessária para que as decisões do negócio sejam rápidas, assertivas e sustentáveis.
Na prática: O Projeto “Saúde dos ETLs” na equal
Colocar em prática uma cultura de governança e monitoramento robusta torna-se um desafio complexo em ambientes multicloud. Na equal, trabalhamos com diversos provedores de nuvem e serviços distintos, adaptando-nos à infraestrutura de cada cliente. Por exemplo, enquanto em um projeto executamos extrações em uma VM no Azure, em outro processamos os dados no Databricks ou utilizamos o Dataproc do Google Cloud.
Essa diversidade rapidamente nos apresentou um desafio central: como monitorar todos os processos que rodam em plataformas tão distintas e que geram logs desconexos?
Foi desse problema que surgiu a ideia de criar uma pipeline de monitoramento interna, projetada para gerar logs padronizados e reuni-los em uma única infraestrutura centralizada na equal.
Como muitos dos processos que desenvolvemos utilizam Python, criamos uma biblioteca interna que pode ser instalada em qualquer plataforma via pip install. Esta biblioteca captura os logs das execuções e os envia para um webhook protegido, que por sua vez salva os dados em nossa infraestrutura unificada.
Este webhook, além de receber os logs via biblioteca Python, também é compatível com as notificações nativas do Databricks e de qualquer outro serviço que consiga enviar uma requisição POST.
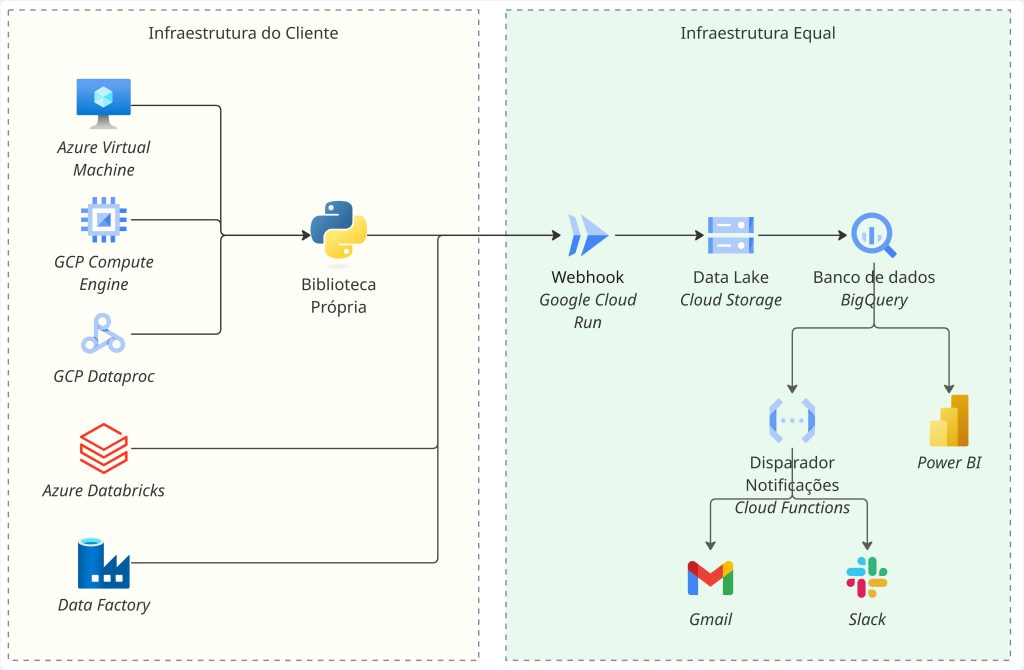
Após os dados serem uniformizados e centralizados neste repositório, desenvolvemos dashboards e notificações personalizadas. Isso nos permite monitorar todos os projetos e todas as execuções em um só lugar, garantindo a saúde dos pipelines e a qualidade dos dados entregues aos nossos clientes.
ETL e a jornada data-driven: do caos à clareza
Toda empresa que decide seguir o caminho da cultura data-driven passa por um mesmo desafio inicial: o caos dos dados. Informações duplicadas, indicadores que não batem, sistemas que não se conversam e relatórios que demoram a chegar. Esse cenário é comum — e é justamente ele que o ETL ajuda a transformar em clareza, confiança e eficiência.
O ETL é o elo entre a engenharia de dados e a estratégia de negócio, o que o torna essencial para qualquer organização que queira evoluir na jornada de maturidade analítica. Essa jornada não se constrói apenas com ferramentas sofisticadas, mas com processos bem estruturados.
O ETL é o primeiro passo para isso: ele cria uma base sólida, onde os dados são extraídos de forma confiável, transformados com qualidade e centralizados com consistência. Ao padronizar os fluxos de dados e garantir integridade entre as fontes, o ETL permite que a empresa avance gradualmente por estágios de maturidade:
- Do operacional ao analítico – quando relatórios deixam de ser tarefas manuais e passam a ser automatizados.
- Do analítico ao preditivo – quando dados limpos alimentam modelos que antecipam tendências.
- Do preditivo ao prescritivo – quando as decisões passam a ser orientadas por algoritmos e insights em tempo real.
Em outras palavras, não há inteligência de negócio sem dados estruturados, e não há estrutura sem um ETL confiável. É ele quem sustenta a escalada da empresa rumo a decisões baseadas em evidências — e não em percepções isoladas.
Quando o ETL funciona bem, a diferença é sentida em todos os níveis da organização. Os relatórios se tornam mais ágeis, os dashboards refletem a realidade e as áreas passam a falar a mesma língua.
Em empresas maduras, o ETL não é apenas um processo — é parte da rotina, do mindset e da operação. Ele traduz a mentalidade data-driven em prática: dados que fluem com confiança geram decisões que movem o negócio com segurança.
Empresas que investem nessa base não apenas otimizam seus processos — elas constroem uma vantagem competitiva sustentável. Porque, no fim, não existe decisão inteligente sem dados confiáveis — e não existe dado confiável sem ETL.
💡 Perguntas Frequentes sobre ETL
O que significa ETL e para que serve?
ETL é a sigla para Extract, Transform, Load (Extrair, Transformar e Carregar). O processo serve para mover e preparar dados de diferentes fontes, garantindo que cheguem limpos, padronizados e prontos para análise em um ambiente centralizado, como um data warehouse ou lakehouse.
Qual a diferença entre ETL e ELT?
A diferença está na ordem das etapas. No ETL, os dados são transformados antes de serem carregados. No ELT, são carregados primeiro e transformados dentro do próprio ambiente de destino — geralmente uma plataforma em nuvem de alta performance, como Databricks ou BigQuery.
Por que o ETL é importante para uma empresa data-driven?
Porque ele assegura a confiabilidade e integridade dos dados usados em relatórios, dashboards e modelos de IA. Sem um ETL bem estruturado, as análises perdem consistência e as decisões de negócio podem ser baseadas em informações incorretas.
Quais são as boas práticas para garantir um ETL eficiente?
Entre as principais estão: padronização de formatos e nomenclaturas, validação de dados em cada etapa, documentação e versionamento dos pipelines, governança e segurança conforme a LGPD, e monitoramento constante da performance dos processos.
Como a equal monitora a saúde dos seus ETLs?
A equal desenvolveu o projeto interno “Saúde dos ETLs”, uma pipeline de monitoramento que centraliza logs de diferentes plataformas (Azure, Databricks, Google Cloud, etc.) em uma infraestrutura unificada. Isso garante visibilidade, confiabilidade e qualidade contínua dos dados entregues aos clientes.

